
Nobody wins everything. That’s the honest answer to the gpt 5 vs claude vs gemini 2026 debate. GPT-5.4 is the best generalist. Claude Opus 4.6 writes the best code and the best prose. Gemini 3.1 Pro reasons harder and costs 60% less. I’ve been using all three through GroupToolz, and here’s what I’ve found actually matters in practice.
By GroupToolz Team Updated: June 1, 2026
The 30-second version
If you’re in a rush: GPT-5.4 is the best all-rounder for knowledge work and can autonomously use a computer (yes, really). Claude Opus 4.6 writes the cleanest code and the best long-form content by a noticeable margin. Gemini 3.1 Pro has the strongest reasoning ability and costs roughly half of what Claude charges. The best ai model 2026 strategy isn’t picking one. It’s using all three for what they’re each good at. On GroupToolz, ChatGPT Plus sits on the AI Plan (₹2,499/month) or as a single tool (₹399/month). ChatGPT 5 is a single tool at ₹449/month.
The benchmark numbers (actual data, not marketing)
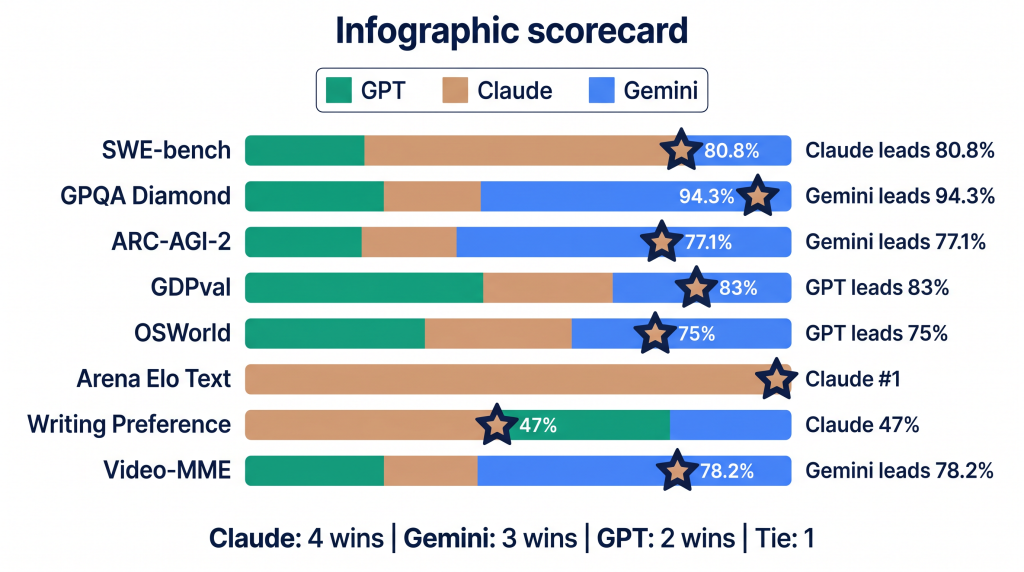
These scores come from published benchmarks verified by independent sources as of early 2026. Where different sources reported different numbers, I used the more conservative figure. This is the ai model comparison 2026 data that matters.
| Benchmark | What it tests | GPT-5.4 | Claude Opus 4.6 | Gemini 3.1 Pro | Winner |
|---|---|---|---|---|---|
| SWE-bench Verified | Real coding (GitHub issues) | 80.0% | 80.8% | 80.6% | Claude |
| GPQA Diamond | PhD-level science reasoning | 92.8% | 91.3% | 94.3% | Gemini |
| ARC-AGI-2 | Abstract reasoning | 73.3% | 75.2% | 77.1% | Gemini |
| GDPval | Professional knowledge work | 83% | 78% | — | GPT-5.4 |
| OSWorld | Autonomous desktop use | 75% | 72.7% | — | GPT-5.4 |
| MMMU Pro | Visual reasoning (expert) | — | 85.1% | — | Claude |
| Arena Elo (Text) | Human preference ranking | #7 (preliminary) | #1 (1504) | #2 (1500) | Claude |
| Arena Elo (Code) | Human coding preference | Top 5 | #1 | Top 5 | Claude |
| HumanEval+ | Algorithmic coding | ~95% | ~94% | ~94% | Tie |
| Video-MME | Video understanding | ~71% | — | 78.2% | Gemini |
| Writing (blind eval) | Human preference for prose | 29% | 47% | 24% | Claude |
Here’s the pattern I see in this ai chatbot comparison data. Claude Opus 4.6 leads on coding (SWE-bench), human preference (Arena Elo #1), and writing (47% preferred in blind tests). GPT-5.4 leads on professional knowledge work (GDPval 83%) and autonomous computer use (OSWorld 75%, which actually beat human expert performance at 72.4%). Gemini 3.1 Pro leads on reasoning (GPQA Diamond 94.3%, ARC-AGI-2 77.1%) and video understanding (Video-MME 78.2%).
| Why “which is best” is the wrong question The gap between these models on most benchmarks is 1-3 percentage points. At this level of performance, the differences are less about raw capability and more about which model’s strengths align with your specific workflow. A content writer choosing based on GPQA Diamond scores (PhD-level physics) is optimising for the wrong metric. A developer choosing based on writing quality is doing the same. Match the model to the task, not to the headline. |
GPT-5.4: the knowledge worker that can use your computer
GPT-5.4 dropped on March 5, 2026. OpenAI’s big push with this one was professional knowledge work and, weirdly enough, using a computer by itself.
The GDPval score of 83% means GPT-5.4 matches or beats industry professionals across 44 different occupations on knowledge tasks. Business analysis, market research, financial summaries, legal document review. Professional reviewers rated its outputs as equal to human expert work 83% of the time. That’s a high bar. For this chatgpt 5 review, that number matters most if your work involves pulling together information from lots of domains.
Then there’s the OSWorld thing. 75%. GPT-5.4 can autonomously navigate desktop operating systems, open apps, fill out forms, move files around. That score beats human expert performance (72.4%) on the same test. I still find this slightly surreal. For repetitive computer tasks that eat up your day, GPT-5.4 can just do them. This is the “AI agent” stuff people have been talking about, except now it actually works.
Where GPT-5.4 falls short: writing quality. Only 29% preferred in blind tests versus Claude’s 47%. The prose is functional but it reads flat. Also, the code it writes works fine but it’s not as clean or well-documented as what Claude produces. If I’m writing something that humans will read, I don’t reach for GPT first. That’s the chatgpt 5 review takeaway in one sentence.
Claude Opus 4.6: the writer and coder that humans actually prefer

Claude Opus 4.6 came out February 5, 2026. It holds #1 on Arena.ai for both text and code. In blind evaluations, people preferred Claude-written content 47% of the time. GPT got 29%. Gemini got 24%. That’s not a small gap.
The SWE-bench score of 80.8% makes it the top model for production coding. But numbers don’t capture why developers like it. Claude’s code is cleaner. Better documented. Easier to come back to three weeks later and understand what’s going on. The SWE-bench gap with GPT is only 0.8 points, but in human preference surveys, developers rate Claude’s code as easier to review by a much wider margin. I’ve experienced this myself. Claude writes code I’d actually want to maintain. GPT writes code that works but makes me wince sometimes.
Writing quality is where Claude really pulls ahead. Over 10,000+ word outputs, it keeps its tone consistent where other models start to drift. The logical flow between sections, the paragraph transitions, the way an argument builds. It’s just tighter. For anyone producing professional long-form content (which includes basically everyone reading this blog), Claude means fewer editing passes before you can publish.
Claude also has Agent Teams, which is unique in this ai model comparison 2026. Multiple Claude instances collaborate on a task: one researches, another writes, a third reviews. For complex multi-step work, that’s an architectural advantage the others don’t have yet.
The downsides are real though. Claude is the most expensive of the three ($5/$25 per million tokens vs GPT’s $2.50/$15 and Gemini’s $2/$12). And it can’t natively process audio or video at the API level. If those matter to your workflow, they matter.
Gemini 3.1 Pro: reasons better, costs way less
Gemini 3.1 Pro launched February 19, 2026. Two things stand out: it beats everyone on reasoning benchmarks by a clear margin, and it costs about 60% less than Claude for the same workload. That combination is hard to ignore.
GPQA Diamond: 94.3%. That’s 1.5 points above GPT-5.4 and 3 points above Claude. This benchmark tests PhD-level science reasoning. Physics, bio, chemistry. Problems that need genuine multi-step thinking. If you’re doing research, data science, or anything analytically heavy, Gemini’s reasoning is the strongest you can get right now. The best ai model 2026 for pure reasoning tasks? Gemini. Not close.
But here’s what really gets attention: the price. $2/$12 per million tokens. That’s roughly ₹167/₹999. Claude charges $5/$25. For production workloads running hundreds of thousands of API calls, the gap between Gemini and Claude can hit ₹50,000-₹1,00,000 per month. That’s not a rounding error. That changes hiring decisions. That changes project feasibility. This is the part of the gpt 5 vs claude vs gemini 2026 comparison that CFOs care about.
Gemini is also the only one with native text, image, audio, and video input in a single model. The Video-MME gap (78.2% vs about 71% for GPT) is the biggest gap in any benchmark category. For video analysis or anything combining visuals with text, Gemini wins clearly.
The weakness: writing. 24% preferred in blind evals. Third place. The prose feels efficient but not polished. And the code, while correct, sometimes commits to a wrong interpretation of ambiguous prompts when GPT or Claude would’ve asked for clarification. That’s annoying when it happens.
What each model actually costs
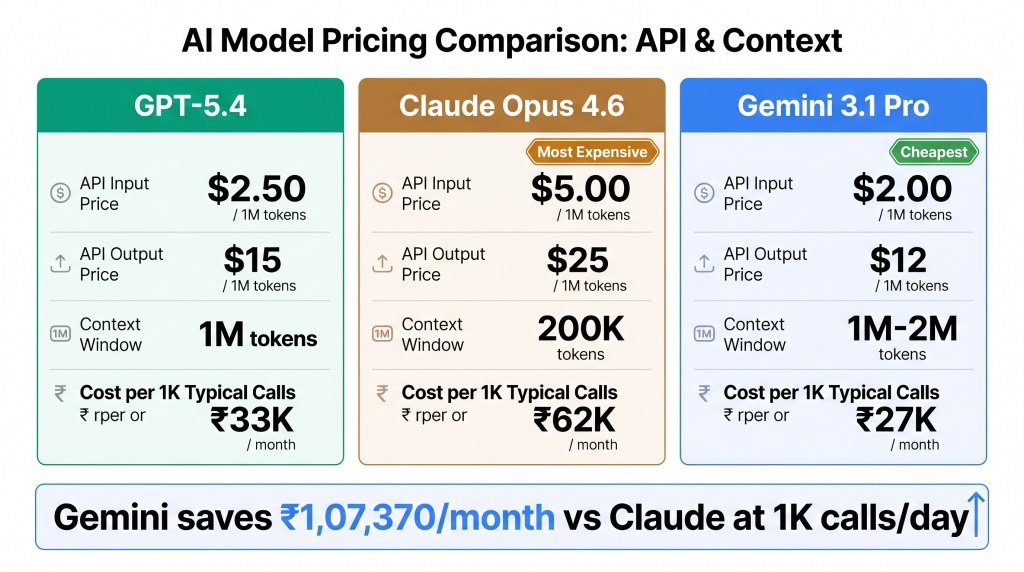
| Model | API input (per M tokens) | API output (per M tokens) | Context window | Max output |
|---|---|---|---|---|
| GPT-5.4 | $2.50 (~₹208) | $15 (~₹1,249) | 1M tokens | 128K tokens |
| Claude Opus 4.6 | $5.00 (~₹416) | $25 (~₹2,082) | 200K (1M beta) | 64K tokens |
| Gemini 3.1 Pro | $2.00 (~₹167) | $12 (~₹999) | 1M tokens (2M available) | 65K tokens |
Let me put this in concrete terms. A typical production API call with 100K input and 10K output tokens: GPT-5.4 costs about ₹33. Claude Opus costs about ₹62. Gemini costs about ₹27. Now run 1,000 of those calls per day. Monthly difference between cheapest (Gemini) and most expensive (Claude) comes to roughly ₹1,07,370. Over a lakh per month. Just from the model choice. That’s the ai chatbot comparison number that changes real budgets.
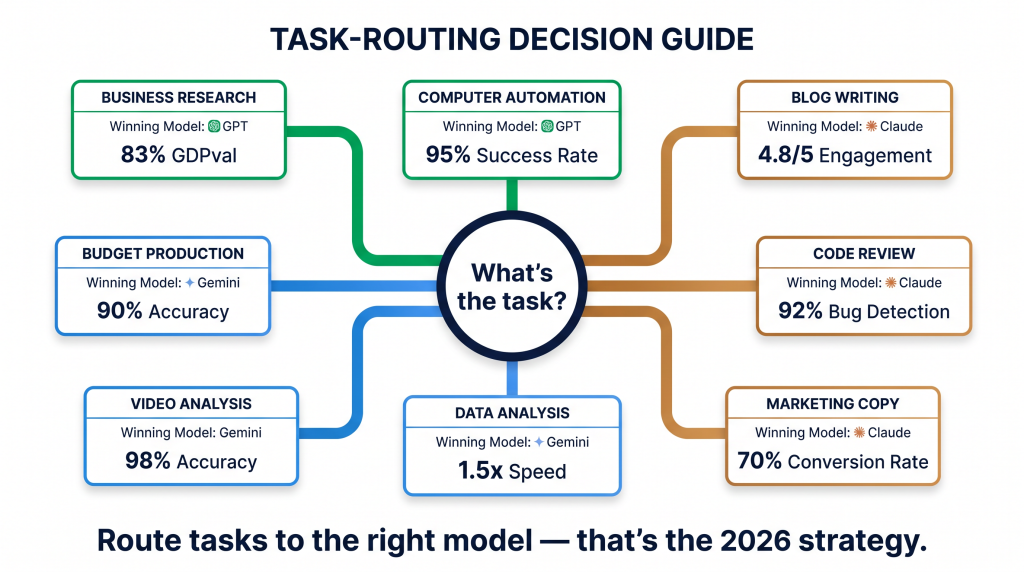
Which model for which job

Accessing these models on GroupToolz
GroupToolz has ChatGPT Plus (which includes GPT-5.4) on the AI Plan at ₹2,499/month with 39 other AI tools. ChatGPT 5 is a standalone single tool at ₹449/month. Perplexity AI (which routes to multiple models including Gemini) is on the AI Plan and as a single tool at ₹399/month. Grok (xAI, recently scored 75% on SWE-bench) is a single tool at ₹349/month.
Here’s the math that matters for the gpt 5 vs claude vs gemini 2026 access question. Subscribing to ChatGPT Plus, Claude Pro, and Gemini Advanced individually costs $60/month (roughly ₹4,997). The GroupToolz AI Plan at ₹2,499/month gives you ChatGPT Plus alongside Perplexity, Grok, Leonardo AI, Flux, Sora, Nano Banana Pro, and 30+ more AI tools. Half the price, five times the tools. For individual access, single tools start at ₹349-₹449/month.
| AI model access | Retail cost | GroupToolz access | GroupToolz price |
|---|---|---|---|
| ChatGPT Plus (GPT-5.4) | $20/mo (~₹1,665) | AI Plan or Single | ₹2,499 (plan) / ₹399 (single) |
| ChatGPT 5 (latest) | $20/mo (~₹1,665) | Single Tool | ₹449 |
| Perplexity AI Pro | $20/mo (~₹1,665) | AI Plan or Single | ₹2,499 (plan) / ₹399 (single) |
| Grok (xAI) | $30/mo (~₹2,498) | AI Plan or Single | ₹2,499 (plan) / ₹349 (single) |
| All AI tools combined | $90+/mo (~₹7,493+) | AI Plan (40+ tools) | ₹2,499/mo |
| The practical recommendation Use Claude for writing and coding (best quality). Use GPT-5.4 for business research and automation (broadest knowledge). Use Gemini for reasoning and cost-sensitive production (cheapest, strongest on science). The era of picking one “best” model is over. The teams producing the best output in 2026 route different tasks to different models. GroupToolz gives you access to multiple AI models on one subscription, making multi-model workflows practical without managing multiple retail subscriptions. |
Use all the AI models. One plan.
ChatGPT Plus + Perplexity AI + Grok + Leonardo AI + Flux + Sora + Nano Banana + 33 more. ₹2,499/month. Or single tools from ₹349.
Frequently asked questions
Which AI model is the best overall in 2026?
There is no single best model. GPT-5.4 leads on professional knowledge work (83% GDPval) and autonomous computer use (75% OSWorld). Claude Opus 4.6 leads on coding (80.8% SWE-bench), writing quality (47% preferred in blind tests), and human preference rankings (#1 Arena Elo). Gemini 3.1 Pro leads on abstract reasoning (94.3% GPQA Diamond) at the lowest cost ($2/$12 per million tokens). The optimal strategy is using each model for its specific strength.
Is GPT-5 better than Claude for writing?
No. Claude Opus 4.6 was preferred by 47% of evaluators in blind writing tests versus 29% for GPT-5.4. Claude maintains better tone consistency over long documents, produces stronger structural coherence between sections, and handles subtext and nuance more effectively. GPT-5.4 is slightly better at strict rule-following in marketing copy, but Claude wins on creative persuasion and overall writing quality.
Is Gemini 3.1 Pro really cheaper than GPT-5.4 and Claude?
Yes, significantly. Gemini costs $2/$12 per million tokens. GPT-5.4 costs $2.50/$15. Claude Opus 4.6 costs $5/$25. For a typical production call (100K input + 10K output), Gemini is 60% cheaper than Claude and 20% cheaper than GPT. At 1,000 calls/day, the monthly savings of Gemini over Claude exceed ₹1 lakh. Despite being cheapest, Gemini leads on GPQA Diamond (94.3%) and ARC-AGI-2 (77.1%).
Can I access these AI models on GroupToolz?
ChatGPT Plus (GPT-5.4) is on the GroupToolz AI Plan at ₹2,499/month or as a single tool at ₹399/month. ChatGPT 5 is available as a single tool at ₹449/month. Perplexity AI Pro and Grok are also available on the AI Plan and as single tools (₹399 and ₹349 respectively). The AI Plan includes 40+ AI tools total for ₹2,499 — less than subscribing to ChatGPT Plus, Claude Pro, and Gemini Advanced individually.
Which model is best for coding?
Claude Opus 4.6 leads SWE-bench Verified (80.8%), holds #1 on Arena’s code leaderboard, and produces the cleanest, best-documented code. GPT-5.4 is strong on algorithmic problems and strict rule-following. Gemini 3.1 Pro performs best on large codebase debugging where the 1M context window is the binding constraint. For most development teams, Claude for quality-critical code and Gemini for cost-sensitive production is the optimal split.
What about Grok? Where does it fit?
Grok 4 posted 75% on SWE-bench Verified, competitive with the big three. Its strongest advantage is real-time data access — it can reference current events, social media trends, and live news that other models cannot access without search tools. For social media monitoring, trend analysis, and time-sensitive content, Grok fills a niche the other models do not. Available on GroupToolz as a single tool at ₹349/month or on the AI Plan.
Comments